What Makes Content Adaptive?
A practical guide for content teams getting their library ready for an adaptive product, with a deep dive into the learning objectives that everything else hangs from.

Adaptive learning has shifted from a niche idea to a mainstream expectation. Recent reviews of AI enabled adaptive learning platforms describe systems that dynamically adjust instructional content and pathways by collecting and analysing learner data. Newer work goes further, applying LLM powered analytics to adapt learning pathways and recommend resources aligned to each learner’s progress.
But the technology is only as good as the content underneath it, and especially the learning objectives that organise that content. An adaptive engine cannot personalise its way out of vague, compound or unmeasurable objectives. If your objectives are loose, every downstream decision the system makes is loose too.
This guide is for content teams getting their library ready for an adaptive product. It covers the five properties that distinguish adaptive content from regular content, and the part teams most often underestimate: how to design the learning objectives that everything else hangs from.
What adaptive content actually means
There is a common misunderstanding that adaptive content is content that gets generated on the fly. It is not. Adaptive content describes two things working together:
- The properties of the content itself, the structural choices that let a system reason about it.
- The clarity of the learning objectives it is organised around, because the objective is the unit the engine tracks proficiency against, recommends towards, and reports on.
The technology is only as good as the content underneath it, and especially the learning objectives that organise that content. An adaptive engine cannot personalise its way out of vague, compound or unmeasurable objectives.
You cannot bolt one onto the other later.
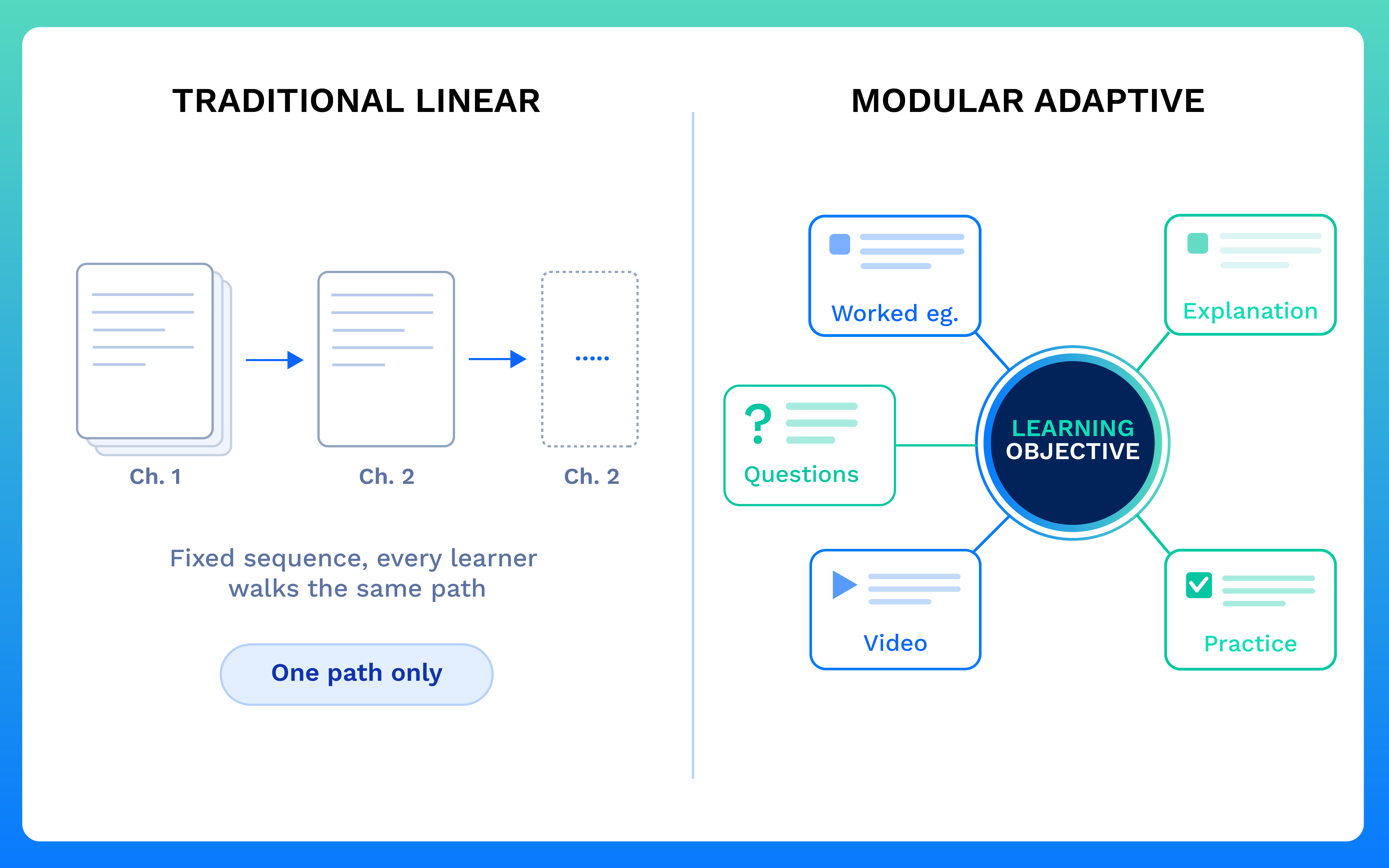
The five properties of adaptive content
Five qualities decide whether a piece of content behaves well in an adaptive system. Most teams already do some of this implicitly. The shift is doing it deliberately and consistently.
Granularity
Granularity is about the level at which things are tracked, recommended and observed. There are three linked layers: observation granularity (how small is the smallest interaction you capture?), recommendation granularity (what is the smallest unit you can serve?), and proficiency granularity (what is the smallest skill you can score a learner against?). If you only capture a single score for a ten question quiz, you cannot infer proficiency on any individual skill the quiz covers. The point is not to chop everything into tiny fragments; it is to make sure the unit you track is the unit you can meaningfully reason about.
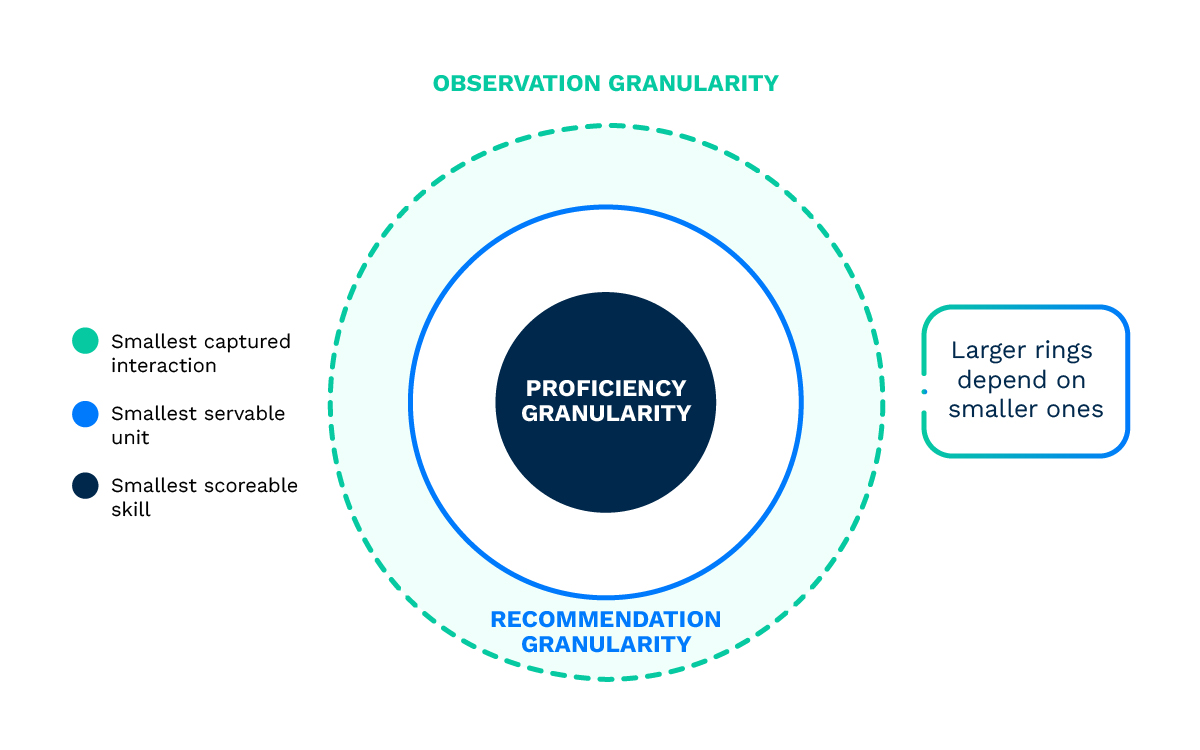
Modularity
Modular content does not assume a fixed path. Each item should stand on its own enough that the engine can serve it without requiring the learner to have just finished a specific previous item. This does not mean abandoning structure; modular content can still scaffold and respect prerequisites. It means a learner who is weak on a particular skill can receive practice on exactly that, without first walking through five unrelated chapters.
Alignment
Alignment is the relationship between instructional content (the teaching) and assessment content (the measuring). For every learning objective, the questions used to assess it should genuinely measure what the instruction taught, and the instruction should cover what the assessment will check. Misalignment is one of the most common defects in legacy libraries, often because instruction and assessment were authored at different times by different teams against slightly different interpretations of the same outcome.
Discreteness
Discreteness asks: does each piece of content teach to, or assess, one explicit outcome? A course with discrete content has minimal overlap among both its learning objectives and the content aligned to those objectives. Discreteness does not mean objectives are unrelated; in many cases they build on one another. The point is that content should be developed around distinct learning objectives so that instruction and assessment can be more targeted and precise.

Volume
For every learning objective, the practical baselines are: 2 to 3 instructional items so the system can present the same idea in different ways; 15 questions as a recommended target for assessment depth; and 5 questions as the minimum needed to estimate proficiency reliably. Volume is not just “having enough content”. It is giving the engine room to vary what it shows, and providing the conditions for spaced retrieval practice to work.
Instructional items
So the system can present the same idea in different ways for learners who did not get it first time
Minimum questions
The floor the system needs to estimate proficiency reliably
Target questions
Recommended for assessment depth, enough to space retrieval practice without repeating items
The heart of the work: designing learning objectives
If there is one place where content teams get the most leverage, it is here. Everything else in this guide is downstream of how well your learning objectives are written.
Get the vocabulary straight
The terms in this space are used loosely, which is part of why teams talk past each other. Three layers, three jobs:
- Goal: the broad ambition (e.g. “Develop algebraic reasoning”)
- Outcome: what is measured at unit or course end (e.g. “Solve linear equations in one variable”)
- Objective: what the learner can do at the end of one lesson (e.g. “Isolate a variable in a two step linear equation by applying inverse operations”)
The objective is the unit an adaptive system actually tracks. Get this layer right and the rest follows.
Start with backward design
Before writing any learning objective, agree the assessment that would prove a learner has mastered it. This is the core of backward design, popularised by Wiggins and McTighe and now standard practice across the field. Backward design is a three stage approach: define desired results, determine acceptable evidence of learning, and only then plan learning activities.
In adaptive content, this matters twice over: the objective drives the assessment, and the assessment produces the data the engine learns from. If you cannot picture the question that would prove mastery, the objective is not yet ready to write.
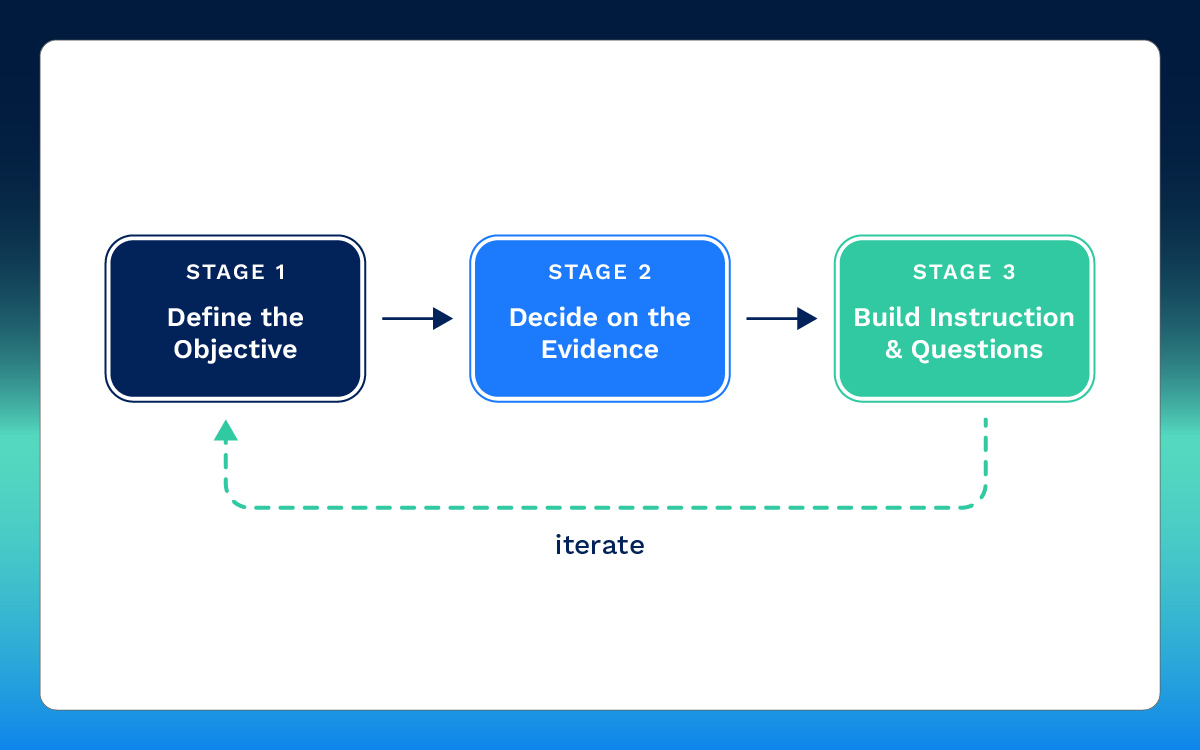
Use the A-SMART formula
Recent work has refined the classic SMART rubric into “A-SMART”, emphasising that outcomes should begin with an action verb to make them immediately measurable: Action oriented, Specific, Measurable, Attainable, Relevant, Time bound. A useful supplementary structure is the ABCD model: Audience, Behaviour, Condition, Degree. Most well written objectives implicitly contain all four.
“Students will understand fractions.”
“Given a fraction with an unlike denominator, learners will compute the equivalent fraction with a specified target denominator, with at least 80% accuracy across five problems.”
The second one tells you, the engine, and the learner exactly what success looks like.
Pick verbs that can be observed
Action verbs do most of the work in a learning objective. The single most common defect in legacy objectives is the use of verbs that cannot be observed or graded. Avoid verbs like “understand”, “appreciate”, or “know” and replace them with verbs you can measure:
| Avoid | Try instead |
|---|---|
| understand | explain, describe, summarise |
| know | identify, list, define |
| appreciate | justify, defend, evaluate |
| be familiar with | recognise, label, classify |
| learn about | apply, calculate, demonstrate |
If you cannot picture the test question that would measure the verb, change the verb.
Use Bloom’s revised taxonomy to set the level
The revised Bloom’s Taxonomy uses active verbs (Remember, Understand, Apply, Analyse, Evaluate, Create) to clearly define measurable learning objectives. For an adaptive product, Bloom’s gives you two things at once: a consistent level tag for every objective that becomes useful metadata, and a check on whether your instruction matches your assessment. If the objective is at “Apply” level but every assessment item is “Remember”, you are not measuring what you wrote.
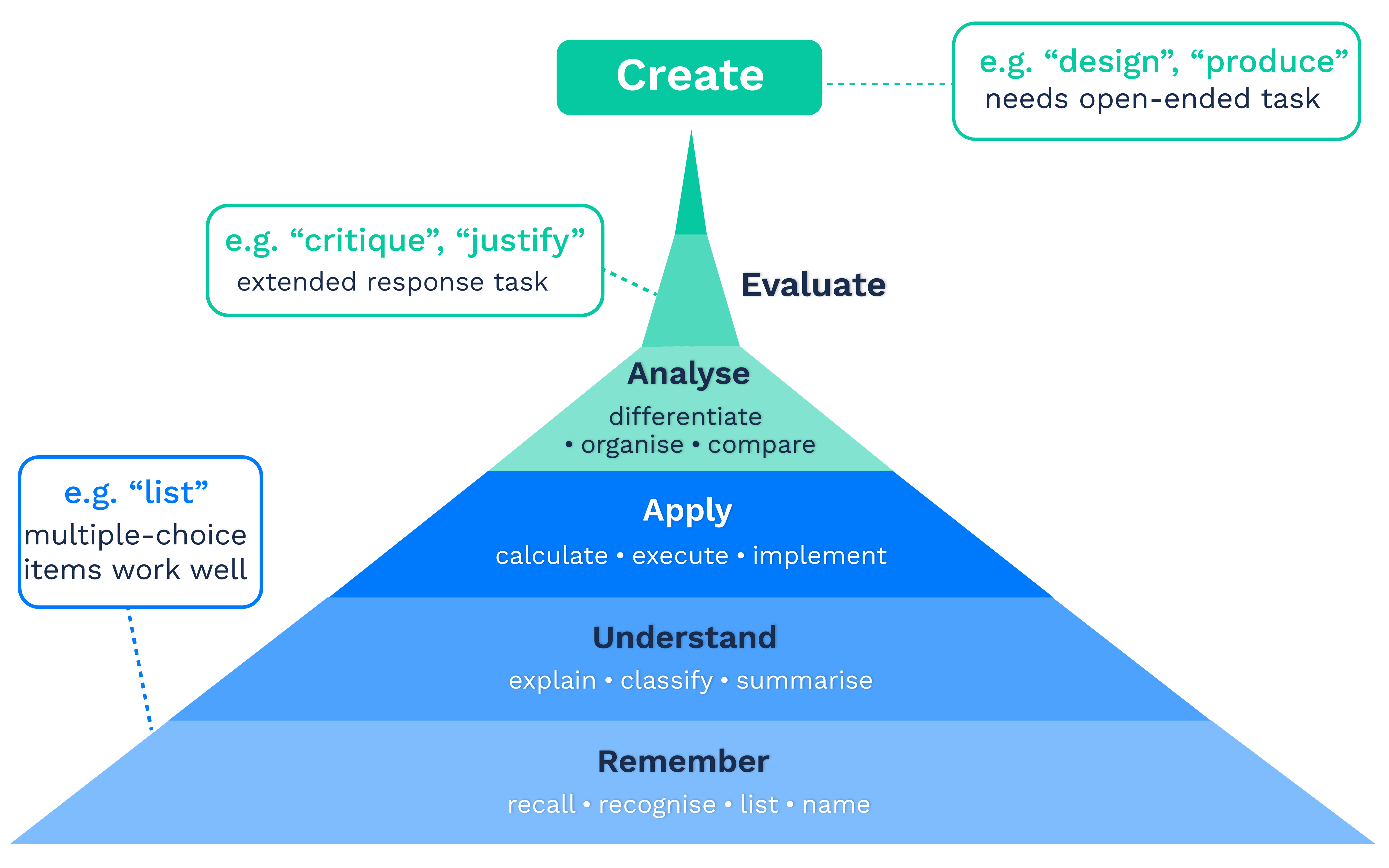
One objective, one outcome
Compound objectives are a quiet killer. “Identify and explain the causes of the French Revolution” looks like one objective; it is two. Identifying is at Remember level; explaining is at Understand level. A multiple choice question can measure the first; a short answer response is needed for the second. Compound objectives produce muddled proficiency estimates because a learner can succeed on one half and fail on the other and the engine cannot tell which.
One verb per objective. If your draft has an “and” in the middle, split it.
The right grain size: lesson scope, not unit scope
There is a temptation to write objectives at the unit or chapter level, partly because that is where syllabus documents live, partly because writing many lesson level objectives is more work. Resist it. Lesson scope is the level at which instruction and assessment can both fit on the same page, the verb genuinely describes one observable behaviour, and the volume targets make sense. Unit scope objectives are still helpful as a navigation aid for the wider course, but they are not the unit the engine works against.
The pedagogical underpinnings worth knowing
The volume targets earlier are not arbitrary; they sit on top of three well established findings from cognitive science.
Cognitive load theory. Working memory has a fixed capacity. A single, focused objective per lesson keeps intrinsic load manageable and gives the learner space to process rather than merely receive.
The worked example effect. For novices exposed to information for the first time, worked examples are better than problem solving, though this effect reverses as experience grows. Per objective volume should include at least one worked example alongside practice questions. An adaptive engine that has both can serve worked examples to learners who are struggling and pure practice to learners who are progressing.
Retrieval practice and spacing. Decades of evidence support the testing effect: pulling information out of memory is more powerful than re-reading it, and spacing those retrievals over time consolidates learning more durably. This is the deeper reason the assessment volume target is closer to fifteen than five: it gives the engine enough material to space practice properly without showing the same item twice in quick succession.
Stable identifiers and a version rule
Every learning objective should have a stable unique identifier that lives for the life of the objective, and a written rule for when an edit is significant enough to count as a new objective rather than a revision. The engine attaches everything (proficiency, recommendations, analytics) to that identifier. Silently changing what an objective means while keeping the same ID poisons every metric attached to it. The rule does not have to be sophisticated; it just has to exist and be followed.
Volume rules of thumb
For every learning objective, aim for:
- At least 2 to 3 instructional items, ideally with different angles or formats: a worked example alongside an explanation, a short video alongside text
- At least 5 assessment items, the floor for any reliable proficiency estimate
- Closer to 15 assessment items for robust diagnosis without learners seeing the same questions repeatedly, and to give the engine room to space retrieval practice properly
If you cannot hit these targets across your library, that is a planning conversation, not a blocker. Some objectives matter more than others; some need more depth.
Lean on the syllabus, don’t reinvent it
You do not need to invent your taxonomy from scratch. In most subject areas there is already a well established curriculum framework you can map your objectives against. Tag against:
- Cognitive level: Bloom’s revised taxonomy
- National curriculum: Common Core, the Australian Curriculum (ACARA), Cambridge syllabi, the CEFR for languages
- Subject specific: NGSS for science, AP frameworks, IB subject guides
- Question type: multiple choice, short answer, free response, drag and drop
The point is interoperability. The 1EdTech CASE standard facilitates the exchange of information about learning and education competencies between systems. The Quality Matters K-12 rubric is widely used to evaluate whether activities are clearly aligned to objectives and standards. Tagging against established frameworks means your metadata travels: between your products, between systems and between you and any partner you integrate with.

What the latest thinking adds
Three threads from current research are worth folding into how content teams plan.
Recent work has explored using GPT-class models to generate first pass learning objectives from raw course material, suggest candidate objectives at specified Bloom’s levels, and check existing objectives for compound verb defects. The output is plausible enough to be useful as a draft but reliably needs human review: the models are confident in ways that do not always match the underlying pedagogy.
A 2025 framework called ARCHED (A Responsible, Collaborative, Human centered Educational Design system) reimagines human AI collaboration in instructional design by leveraging modern LLM capabilities to enhance, rather than replace, human expertise. The motivating concern is real: recent studies show standardisation of AI generated assessments often results in a narrow range of evaluation methods. The practical implication for content teams is to design explicit review gates at the objective to assessment alignment step not just at draft generation. LLMs can produce plausible objectives quickly; the point of human oversight is checking that the assessment evidence actually proves what the objective claims.
UX research on AI powered adaptive interfaces has identified a critical trade off between learning efficiency and user engagement, mediated by how discoverable and perceived as valuable the adaptive features are. If your objectives carry rich, learner meaningful metadata (Bloom’s level, why this is recommended next, what mastery looks like) the product can show learners why something has been chosen for them. Bare items with thin objective metadata cannot tell that story.
Before tagging objectives with Bloom’s levels or curriculum codes, it is worth doing a quick audit with a fresh eye. How many of your existing objectives contain “understand” or “know”? How many have “and” in the middle? In most legacy libraries, the answer is: most of them. That is where the work starts.
Connecting objectives: prerequisite and extension relationships
The five properties cover how to structure individual objectives well. They do not cover how objectives relate to each other and for an adaptive engine, the relationship graph is where most of the intelligence lives. Once objectives are clean and discrete, the next question is: what does the engine need to know about how they connect?
The label trap
The most common mistake content teams make when approaching this for the first time is trying to solve the relationship problem by creating new types of objectives, “enabling learning objectives”, “sub objectives”, “foundational objectives”. This feels like progress because it produces a taxonomy. It actually makes the problem worse. Creating a new objective type collapses a relationship into a label. Once you call something an “enabling LO”, you have described what it does in relation to something else but you have not recorded what that something else is. The engine cannot traverse a label; it can traverse a link.
Relationships between objectives are metadata on the connection between two nodes, not a property of either node. An objective is not “enabling”; it is a prerequisite of a specific other objective. That relationship must be recorded explicitly, as a link between two identifiers.
The Year 3 / 4 / 5 problem
Traditional content development for a given year level typically produces three content tiers: baseline, advanced, and easier remediation. In a non-adaptive product this works because a teacher selects the tier. In an adaptive product, the same three tiers correspond to something structurally different:
- The “easy” remediation content is often not easier content for the same objective; it is content aligned to a prerequisite objective that may sit in a prior year.
- The “advanced” extension content is often not harder content for the same objective; it is content aligned to an extension objective that may sit in a subsequent year.
When these are filed as difficulty variants of one objective, the engine cannot distinguish between a learner who has not yet reached the prerequisite and a learner who has mastered the current objective and is ready for extension. The fix is not to create three difficulty tiers within an objective. It is to write each objective at lesson scope for the year it belongs to, then record its prerequisite and extension relationships as explicit links.

A lightweight relationship model
Three relationship types cover the vast majority of cases. These should be recorded as explicit links between objective records, not as labels on individual objectives.
| Type | What it records | Priority |
|---|---|---|
| Prerequisite | Objective A must be mastered before objective B can be meaningfully attempted. Link points from B to A. | High, record in first pass |
| Co-requisite | Objectives A and B are typically learned in parallel; neither is strictly prior. Engine can often infer from shared curriculum alignment. | Lower, defer to second pass |
| Extension | Objective B is the natural next step once objective A is mastered. Link points from A to B. | High, record in first pass |
What this means in practice
Adding relationship mapping to the authoring workflow requires one additional step: after writing and validating each objective against the checklist, the author identifies and records any prerequisite or extension relationships to other objectives in the library. This is a content decision that belongs with the author, not with a separate metadata team.
- Prerequisite objective IDs
- Extension objective IDs
Where a prerequisite exists in a prior year level, record the link anyway, even if it points outside the current project scope. A broken link is better than a missing link; at least it is visible and fixable. Co-requisite relationships are lower priority to record explicitly, as the engine can often infer these from shared content alignment. Prerequisite and extension links should be the focus in the first pass.
A pragmatic checklist for objective design
Before declaring a set of learning objectives “adaptive-ready”, work through the following. These are the minimum structural conditions for a content library that an adaptive engine can work with.
Adaptive-ready checklist
- Each objective starts with a measurable action verb
- No objective contains “understand”, “know”, “appreciate” or “be familiar with”
- No objective uses two verbs joined by “and” (no compound objectives)
- Each objective is at lesson scope, not unit or course scope
- Each objective has a Bloom’s revised level tagged
- Each objective is linked to a curriculum standard where one exists
- Each objective is paired with an explicit picture of the assessment that would prove it
- Each objective has a stable unique identifier; without this, any rename or reword breaks the link between the objective record, its aligned items, and the learner performance data tied to it. Once data has accumulated, renaming an objective without preserving its ID is equivalent to starting its data history from zero.
- There is a written rule for “edit vs. new objective”. Note that reclassifying an existing objective as a type (enabling, foundational, etc.) is not a substitute for recording an explicit relationship link.
- Each objective has at least 2 to 3 instructional items, including at least one worked example where applicable
- Each objective has at least 5 assessment items, ideally closer to 15
- Each objective’s prerequisite relationships are recorded with explicit links to the prerequisite objective IDs
- Each objective’s extension relationships are recorded with explicit links to the extension objective IDs
- There is a documented rule for when to record a relationship vs when to create a new objective
If you can tick most of those, you are a long way ahead of where most libraries start.
Where to start with a legacy library
Teams arriving at this guide are almost always sitting on an existing library of hundreds or thousands of items. The checklist above is a destination; these three sweeps give you a triage priority before attempting it in full.
- 1. String search audit. Run a search across your objective records for vague verbs: “understand”, “know”, “appreciate”, “be familiar with”. In most legacy libraries, the answer is: most of them. That is where the rewriting work starts.
- 2. Compound objective scan. Search for objectives containing “and”. Flag each one; it almost certainly contains two objectives that need separating before the engine can score either cleanly.
- 3. Scope check. Sample objectives and ask: is this written at lesson scope, or at unit or course scope? Objectives written too broadly cannot drive meaningful proficiency tracking. Count how many are at unit level rather than lesson level to get a sense of the rework involved.
The honest summary
Adaptive content is not a different kind of content. It is regular content organised around learning objectives that have been written with discipline. The five properties, granularity, modularity, alignment, discreteness and volume, are tools for spotting structural gaps.
The objective design rules are the actual heart of the work: action oriented verbs, Bloom’s level tagging, lesson scope grain size, no compound objectives, and a clear picture of the assessment that would prove mastery.
And once objectives are clean, record how they connect to each other. The prerequisite and extension graph is what the engine actually navigates; a flat list of well written objectives is a good start, but the relationships are what give the engine its routing intelligence.
Get the objectives right and record how they connect. The engine needs both: clean objectives to score against, and a relationship graph to navigate.
References
- Wiggins, G., & McTighe, J. (2005). Understanding by Design (2nd ed.). ASCD.
- Anderson, L. W., & Krathwohl, D. R. (Eds.). (2001). A Taxonomy for Learning, Teaching, and Assessing: A Revision of Bloom’s Taxonomy of Educational Objectives. Longman.
- Li, H., Fang, Y., Zhang, S., Lee, S. M., Wang, Y., Trexler, M., & Botelho, A. F. (2025). ARCHED: A Human Centered Framework for Transparent, Responsible, and Collaborative AI Assisted Instructional Design. Proceedings of Machine Learning Research, 273, 94–104.
Further reading
Guide
Standards alignment for educational publishers
How curriculum mapping works, where workflows break down, and what scalable alignment looks like in practice.
Read moreProduct
Metadata management for educational content
How structured metadata supports alignment, discovery and reuse across publishing workflows.
Read moreArticle
AI assessment for publishers
Is your publishing workflow ready for the AI era? What content operations need to get right before the engine can help.
Read moreReady to discuss your adaptive content workflow?
We work with editorial and product teams to understand how objective design fits into your content operations.